Chapter02 컴퓨터의 구조와 성능향상
1. 컴퓨터의 기본 구성
1.2 폰노이만구조
 이미지 출처 : 위키피디아
이미지 출처 : 위키피디아
CPU, IO장치, 메모리가 버스를 통해 연결되어있는 구조. 오늘날의 컴퓨터는 대부분 폰노이만 구조를 따른다. 하드웨어는 그대로 두고 프로그램만을 메모리에 올려 다양한 작업을 할 수 있게 한 구조이다. 이러한 폰노이만 구조의 가장 중요한 특징은 모든 프로그램은 메모리에 올라와야 실행할 수 있다는 것이다.
1.4 하드웨어 사양 관련 용어
- 시스 템버스 : (=전면 버스, FSB) 메모리와 주변장치들을 연결하는 버스로, 메인보드 외면에 보이는 버스이다. 시스템 버스의 속도가 1.3GHz라면, 주변에 연결되는 램, 보조기억장치 등등도 모드 1.3GHz의 클럭으로 동작하게 된다. 또한 시스템버스의 클럭은 일반적으로 CPU의 것보다 느리다.
- 내부 버스 : (=후면 버스, BSB) CPU 내부의 장치들을 연결하는 버스. CPU의 클럭와 동일하다.
2. CPU와 메모리
2.1 CPU의 구성과 동작
2.1.1 CPU의 기본 구성
아래의 장치들은 CPU 내부의 것들이다.
- 산술논리연산창지(ALU) : 덧셈, 뺄셈 같은 두 숫자의 산술연산과 배타적 논리합, 논리곱, 논리합 같은 논리연산을 계산하는 디지털 회로이다. 산술 논리 장치는 컴퓨터 중앙처리장치의 기본 설계 블록이다.
- 제어장치(contrl unit) : 프로세서의 조작을 지시하는 컴퓨터 중앙 처리 장치(CPU)의 한 부품이다. 입출력 장치 간 통신 및 조율을 제어한다.
- 레지스터 : CPU 내부의 연산중인 값을 보관하는 아주 빠른 기억 장소(장치)이다.
2.1.3 레지스터의 종류
CPU는 필요한 데이터를 메모리에서 가져와 레지스터에 저장후 ALU를 이용해 연산한다. 이후 그 결과를 다시 레지스터에 저장했다가 메모리로 옮인다. 이때 사용되는 레지스터들은 데이터 레지스터와 주소레지스터이며, 가시레지스터라고 부른다.
- 가시 레지스터(user-visible register) : 사용자가 운영체제와 애플리케이션을 통해 수정할수 있는 레지스터들.
- 데이터 레지스터(DR) : 메모리에서 가져오거나 저장할 데이터를 보관하는 레지스터. CPU의 레지스터 중 대부분은 이것이기 때문에 범용레지스터, 일반레지스터라고도 부른다.
- 주소 레지스터(AR) : 처리할 데이터가 저장된 메모리의 주소.
- 특수 레지스터, 사용 불가 레지스터(usesr-invisible register) : 사용자가 조작 불가능한 레지스터들.
- 프로그램 카운터(PC) : 다음에 실행될 명령의 주소를 기억하는 레지스터. 명령어 포인터라고도 한다.
- 명령어 레지스터(IR) : 현재 실행중인 명령을 저장하는 레지스터.
- 메모리 주소 레지스터(MAR) : 읽거나 쓰려고 하는 메모리의 주소를 저장하는 레지스터. 해당 레지스터에 저장된 주소로 데이터를 저장하거나 가지고 온다.
- 메모리 버퍼 레지스터(MBR) : 메모리에서 가져온 데이터나 옮겨갈 데이터가 임시로 저장되는곳. 항상 MAR과 같이 동작한다.
2.1.4 버스의 종류
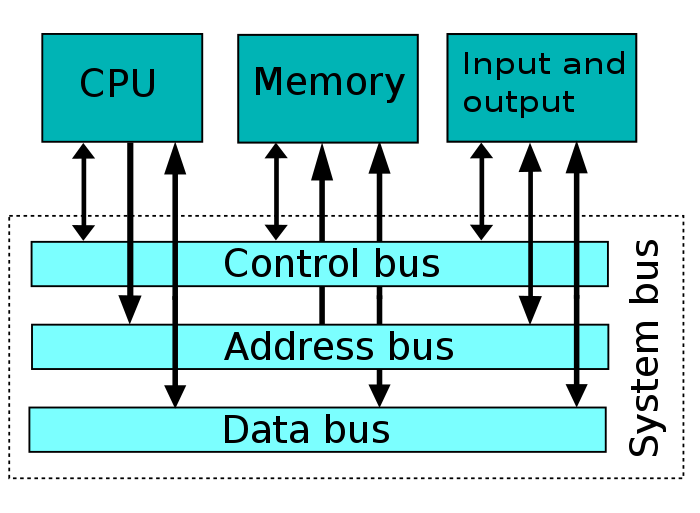 이미지 출처 : 위키피디아
이미지 출처 : 위키피디아
(시스템)버스는 CPU, 메모리, 주변장치간 데이터를 주고 받을 때 사용한다.
- 제어버스 : 작업을 지시하는 제어신호가 오간다. 양향향이다.
- 주소버스 : 어느 위치(메모리)에서 작업할지에 대한 정보(주소)가 오고가는 버스. CPU에서 나와서 메모리/주변장치로만 전달되는 단방향성 버스이다.
- 데이터버스 : 메모리 버퍼 레지스터와 연결되어 있으며, 데이터가 전달되는 버퍼. 양방향성.
버스의 대역폭은 한번에 전달할수 있는 최대 데이터의 크기를 말한다. 이는 CPU가 한번에 처리되는(움직이는) 데이터의 최대 크기를 말한다. CPU 사양중에서 32bit 64bit가 이 뜻이다. 이와 관련된 데이터 크기는 워드이다. 1워드는 한번에 처리 가능한 데이터의 최대크기이며, 64bit cpu의 1워드는 64bit이다.
2.2 메모리의 종류와 부팅
2.2.2 메모리 보호
메모리보호는 각 프로세스의 메모리 영역을 침범하지 않게 하는 것이다. 특히 운영체제 또한 하나의 프로그램이므로, CPU가 다른 프로그램을 처리하는 동안엔 운영체제는 정지된 상태이다. 이때 하드웨어의 도움을 받는다. 동작중인 프로세스가 지정된 레지스터/메모리의 주소범위를 넘어가는 경우 하드웨어는 인터럽트를 발생시켜 CPU에 전달한다. 그러면 CPU는 운영체제를 깨워 해당 프로세스를 강제종료시키면서 인터럽트를 처리한다.
2.2.3 부팅
컴퓨터가 켜지면 운영체제는 메모리에 올라간다. 이것을 부팅이라고한다. 사용자가 컴퓨터를 키면 롬의 바이오스가 실행되며, CPU/메모리/보조기억장치/IO등 주요하드웨어의 동작을 확인한다. 이상이 없으면 바이오스는 보조기억장치의 마스터부트레코드가 가르키는 프로그램을 메모리로 올려서 실행한다. 이 프로그램이이 부트스트랩이며, 보조기억장치 가장 첫번째 섹터(주소?)에 저장되어있다. 메모리에 탑제된 부트스트랩은 운영체제를 메모리로 올리는 작업을 한다.₩
윈도우 부팅 전용 USB를 만드는것은, USB드라이어에 마스터부트레코드를 탭제하는 것이다.
3. 컴퓨터 성능 향상 기술
3.1 버퍼
3.1.1 버퍼란
버퍼는 속도의 차이가 있는 두 장치 사이에서 그 차이를 완화하는 역할을 하는 장치/기술이다. 속도가 다른 다른 장치(CPU->메모리, 입력장치->CPU…)간 데이터를 일정량의 데이터를 모아서 한번에 전송한다. 이 경우 데이터를 한번에 보내므로 비용이 감소하고 보낼때마다 드는 비용을 최소화할 수 있고, 빠른 장치는 느린 장치의 입력을 더 적게 기다릴수 있다.
버퍼와 ‘하드웨어 안전제거’ : USB등에 데이터를 전송할때도 그냥 뽑아버리면 버퍼가 다 차지않아서 문제가 될 수 있다. 따라서 하드웨어 안전제거(flush동작을 함)를 통해 안전하게 남은 데이터를 전송해야한다.
3.1.2 스풀
속도의 차이가 많이 나는 CPU와 입출력장치가 독립적으로 동작하도록 만든 소프트웨어적인 버퍼. 대표적으로 프린터기가 있다. -> 출력시 출력할 문서를 프린터기의 스풀러 공간에 저장하고 이를 인쇄하게 하면 CPU는 속도가 느린 프린터기를 기다릴 필요가 없어진다.
스풀과 버퍼의 차이 : 버퍼는 프로그램들간 공유된다(입출력 버퍼등). 스풀러는 메타적으로, 하나의 스풀러(인쇄물)를 처리중에는 다른 것들은 간섭할 수 없다.
3.2 캐시
3.2.1 캐시의 개념
 이미지 출처 : https://cpuninja.com/cpu-cache/
캐시는 CPU와 메모리 사이에서, 필요한 데이터를 모아서 CPU에 한번에 전송하는 데이터의 일종이다. 캐시는 빠를 CPU와 (시스템 버스 속도의)레모리의 속도 차이를 완화한다.
이미지 출처 : https://cpuninja.com/cpu-cache/
캐시는 CPU와 메모리 사이에서, 필요한 데이터를 모아서 CPU에 한번에 전송하는 데이터의 일종이다. 캐시는 빠를 CPU와 (시스템 버스 속도의)레모리의 속도 차이를 완화한다.
캐시는 메모리내용중 일부를 미리 가져오고, CPU는 메모리에 접근하기전 캐시에 먼저 방문하여 원하는 내용이 있는지 확인한다. 있으면 캐시 히트, 없으면 캐시 미스라고 한다. 이 히트 비율을 캐시 적중률 이라고 하며, 일반적 컴퓨터의 적중률읜 90%정도라고 한다.
캐시의 적중률을 높이는 방법은
- 캐시의 크기를 키운다 : 적중률 증가와 직결되지만, 캐쉬는 고가의 저장장치이므로 몇 메가바이트만 주로 사용한다.
- 앞으로 많이 사용될 데이터를 가져온다 : 현재 실행되는 명령에서 가까운(다음)명령이 사용될 확률이 높다(지역성 이론). 이러한 데이터를 캐시에 가져오면 적중률이 올라간다. -> 이러한 관점으로 볼 때 goto 문은 캐시의 적중률을 떨어트리므로 쓰지 않는 것이 좋다.
3.2.2 즉시쓰기와 지연쓰기
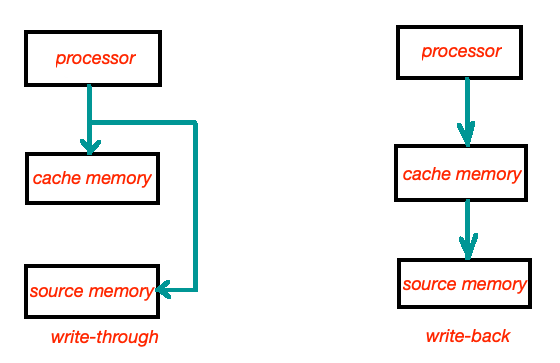 이미지 출처 : student-circuit
캐시에 있는 데이터는 메모리의 있는 데이터를 임시로 가져온것이다. 그러므로 연산을 통해 캐시의 데이터가 바뀌면 원본(메모리)의 것도 바꿔주어야한다.
이미지 출처 : student-circuit
캐시에 있는 데이터는 메모리의 있는 데이터를 임시로 가져온것이다. 그러므로 연산을 통해 캐시의 데이터가 바뀌면 원본(메모리)의 것도 바꿔주어야한다.
- 즉시쓰기 : 캐시에 있는 데이가 변경되면 이를 즉시 메모리에 반영하는 것. 빈번하게 메모리에 접근하므로 성능에 영향을 미치지만 안정성이 높다.
- 지연쓰기 : (=카피백)캐시의 변경내용을 주기적으로 반영하는 방식. 시스템 성능에 영향이 적지만, 안정성이 낮다(불일치 발생 가능성).
3.2.3 L1캐시와 L2캐시
3.2.1의 이미지 참고. 캐시에도 level이 있어서 레지스터와 ㅂ자로 연결된 것을 L1캐시(캐시중 가장 빠름), L1과 메모리(혹은 L3)캐시와 연결된것을 L2캐시(덜 빠름)으로 구분된다.
3.3 저장장치의 계층구조
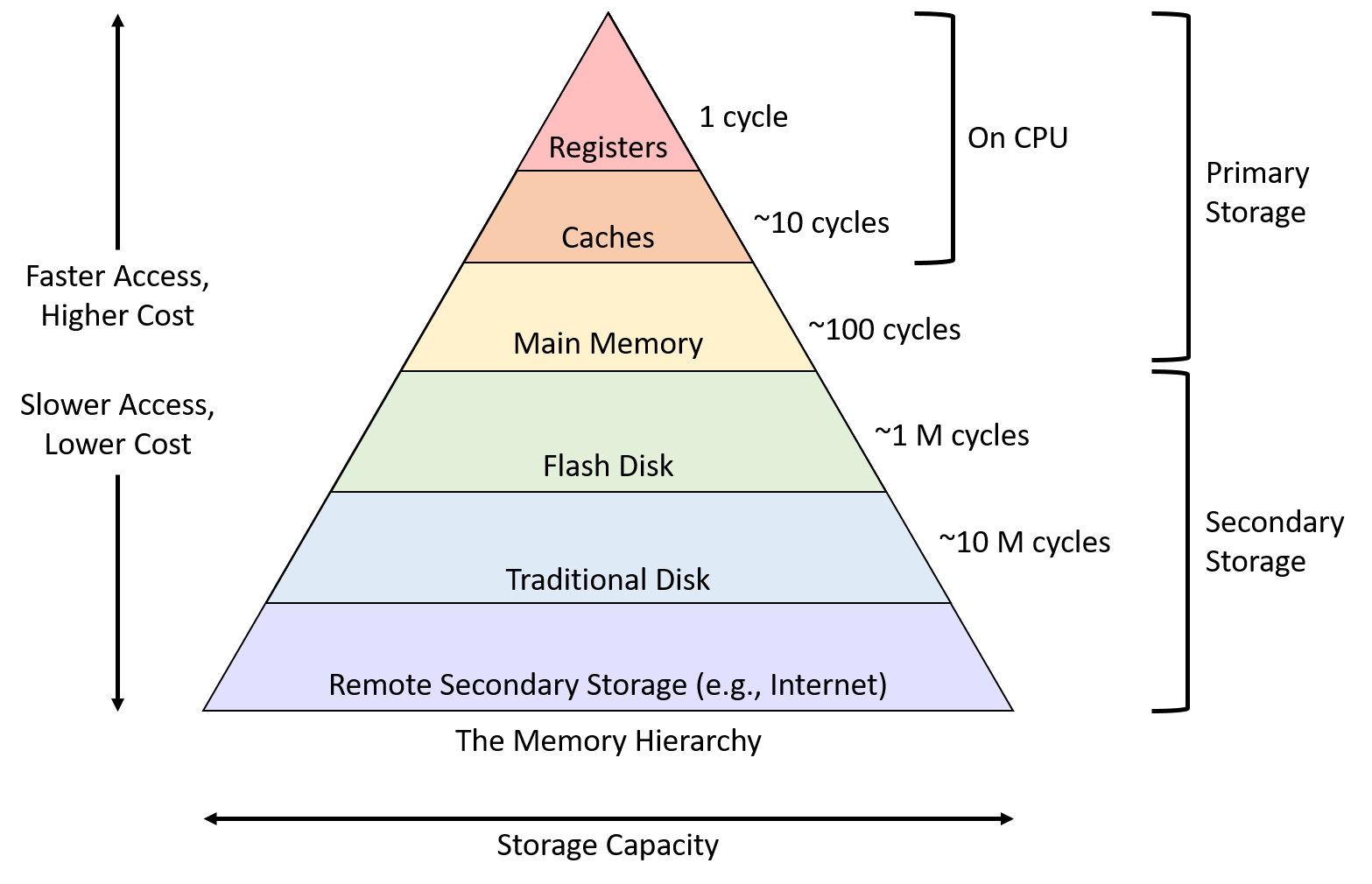 이미지 출처 : diveintosystems
저장장치의 계층구조를 통해 사용자는 저장용량은 보조기억장치처럼, 작업속도는 레지스터처럼 작업할수 있게 된다. 하지만, 이러한 구조로 인해 데이터의 일관성유지, 각 저장장치에 접근 비용이라는 추가적인 비용이 발생하게 된다.
이미지 출처 : diveintosystems
저장장치의 계층구조를 통해 사용자는 저장용량은 보조기억장치처럼, 작업속도는 레지스터처럼 작업할수 있게 된다. 하지만, 이러한 구조로 인해 데이터의 일관성유지, 각 저장장치에 접근 비용이라는 추가적인 비용이 발생하게 된다.
데이터 일관성 : CPU가 캐시의 데이터를 변경하면 메모리의 데이터 또한 바꾸어야 일관성이 유지됨, 보조기억장치간 버퍼…
3.4 인터럽트
3.4.1 인터럽트의 개념
과거에는 CPU에서 직접 입출력장치에 직접관여하여 데이터를 가져오고나 보냈다. 이를 폴링방식이라고 한다. 그러나 폴링방식은 CPU의 효율에 악영향을 미친다. 이러한 악영향을 최소화하기 위해서 인터럽트 방식이 만들어졌다.
인터럽트방식에서는 CPU에 지시만 내리고, 해당 행동이 완료될때 까지 CPU는 다른 행동을 한다. 이후 지시가 완료되면 입출력관리자는 완료 신호를 인터럽트로 CPU에게 보낸다.
3.4.2 인터럽트의 동작과정
- CPU는 입출력관리자에게 입출력 명령을 보낸다.
- 입출력 관리자는 명령받은 동작을 수행한다.
- 동작이 완료되면 입출력관리자는 완료신호를 CPU에 보낸다.
- CPU는 하던일을 멈추고 인터럽트를 처리한다.
- 인터럽트 번호(IRQ) : 각 인터럽트 신호는 장치분류별로 고유의 숫자를 가지고 있다. 이를 인터럽트 번호라고 한다.
- 인터럽트 서비스 루틴(ISR) : 인터럽트 신호가 들어오면 CPU가 어떻게 동작(처리)해야하는지에 대한 코드.
- 인터럽트 백터 : ISR들을 배열형태로 초기화해놓은 메모리 공간.
3.4.3 직접 메모리 접근(DMA)
이미지 출처 : quora CPU가 입출력관리자에게 메모리와 관련된 동작을 지시할때, 입출력관리자는 메모리에 접근해야한다. 하지만 메모리를 CPU이외의 장치가 접근하는것은 위험하므로, 직접메모리 접근제어기를 통해 접근하게 한다. 이러한 방식으로 메모리 관련 동작도 입출력관리자가 수행할수 있게 된다.
3.4.4 메모리 매핑 출력
DMA는 인터럽트 방식 시스템 구성에 필수요소이지만, 이런 DMA를 통해 들어온 데이터는 CPU가 사용하는것과 구분할 필요가 있다. 이를 위해 메모리의 일정 공간을 입출력에 할당한다. 이를 메모리 매핑 입출력(MMIO)라고 한다.
4. 병렬처리
4.1 병렬처리의 개념
현재 CPU의 클럭은 특정 속도(5GHz)를 넘기 힘들다. 이후 CPU의 성능을 늘리기 위해 동시에 실행가능한 명령의 개수를 늘리거나, 코어를 여러개 만드는 방법으로 성능을 향상시켰다.
병렬처리는 동시에 여러개의 명령을 처리할 수 있게 하여 성능을 향상시키는 방법이다. 이러한 병렬처리는 코어가 하나뿐인 CPU에서도 가능하다.
- 스레드 : 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다. 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다.
- 멀티스레드 : 하나의 프로세스 내에서 둘 이상의 스레드가 동시에 작업을 수행하는 것을 의미합니다.
- 멀티 프로세스 : 여러 개의 CPU를 사용하여 여러 프로세스를 동시에 수행하는 것을 의미합니다.
- 파이프라인 기법 : 하나의 프로세스를 독립적인 여러 서브 프로세스로 나누어서, 각 서브프로세스들이 동시에 다른데이터를 취급하며 동시에 동작하게 만드는 기법.
4.2 병렬처리시 고려할사항
- 상호의존성이 없어야 병렬처리가 가능
- 서브 프로세스의 시간이 거의 일정해야 원만한 병렬처리가 가능해짐
- 서프프로세스간의 전환엔 고정비용(오버헤드)이 드므로, 너무 많은 서브프로세스는 성능을 떨어트린다. 참고: 서브프로세스의 개수 = 병렬처리의 깊이
4.2 병렬처리 기법
- 파이프라인 기법
- 슈퍼 스칼라 기법
- 슈퍼파이프라인 기법
- 슈퍼파이프라인 슈퍼스칼라 기법
- VLIW기법
정의 출처 : 위키피디아